최근의 개발 경향은 확실히 마이크로서비스를 지향한다. 가능하면 작은 어플리케이션을 만든다. 그리고 이 어플리케이션들의 소위 콜라보(Collaboration)로 하나의 시스템이 만들어진다. 혹은 만들어지게 구성을 한다. 이와 같은 마이크로서비스 모델이 주는 이점은 나도 몇 번 이야기를 했고, 많은 사람들이 장점에 대해서 구구절절하게 이야기하기 때문에 말을 더 하지는 않겠다.
 여기에서 급질문!! 작은 어플리케이션… 근데 작은 어플리케이션을 지향하는 마이크로서비스의 문제점은 없을까?
여기에서 급질문!! 작은 어플리케이션… 근데 작은 어플리케이션을 지향하는 마이크로서비스의 문제점은 없을까?
먼저 생각나는 첫번째 문제는 작게 만든다고 했으니까 반대급부로 “어플리케이션의 수가 많아진다.” 아닐까 싶다. 지극히 당연한 지적이다. 여기서부터 문제들의 가지를 뻣어나가보자. 뭔가 새로운 걸 만든다면 그럼 이 많은 것들 가운데 연동해야 할 것들이 또한 많다는 것을 의미한다. 잘 외우고 있던지 아니면 잘 적어놔야한다.
많은 대상들과 서로 정보를 주고 받으면 새로운 시스템이 동작해야한다. 대상이 많아지면서 우리는 돌이켜봐야한다. 어울려 일하는 대상과 어떤 방식으로 일을 해야하는지. 일부 처리는 인과 관계가 존재하기 때문에 순서에 맞게 일이 되야 한다. 하지만 특정 작업은 다른 일과 아무 관련성이 없는 경우에는? 개발자의 세상에서 이 상황은 “관련이 없는 이 일과 저 일을 한꺼번에 해도 된다는 것“을 의미한다. 어플리케이션 수준에서 동시에 뭔가를 함께 실행되도록 만드는 건… 생각보다 어렵다.
아래와 같은 통상적인 A, B, C, D, E라는 어플리케이션에 의해 구성된 마이크로서비스를 보자. A 어플리케이션은 “B → C → E” 순서로 다른 어플리케이션과 연동한다. 물론 B, C, E 어플리케이션들도 나름 열심히 연동한다. 이 와중에 D 어플리케이션이 고장되면 어떻게 될까? A 어플리케이션은 과연 문제가 D 때문에 본인의 인생이 꼬인 걸 알 수 있을까?

A는 B 혹은 C 혹은 E의 문제라고 알 것이다. 당연히 A가 직접 연동하는 대상에 D는 포함되어 있지 않기 때문이다. 책임은 전가되고 긴가민가 하는 상황이 길어지면 해결은 안되고 서로 비난하는 상황만 연출된다. D 어플리케이션은 그 와중에 자신이 문제의 핵심이라는 사실을 알지 못할 수도 있다. 이 혼돈은 “문제의 본질을 알지 못한다.“가 최종적인 결론이다.
마이크로서비스 구조가 활발해질수록 당면하게 되는 이슈를 다음의 3가지 어려운 말로 정리해본다.
- 소규모 어플리케이션의 증가로 인한 연동 구조의 복잡성이 증가하고 이로 인한 관리 비용이 증가한다.
- 어플리케이션의 구현 로직이 필연적으로 동기화될 수 밖에 없으며, 상호 독립적인 어플리케이션들의 직렬 실행이 전반적인 성능 저하를 유발시킨다.
- 다중 계층에 의한 연동 구조는 문제 요인에 대한 즉각적인 발견을 어렵게 하며, 핵심 요소의 장애 발생시 시스템 수준의 재앙을 초래할 수 있다.
이렇게 열거해놓고 보니 아무리 마이크로서비스 구조가 좋다고 이야기를 해봐도 연동 계층이 많아질수록 벗어나고 싶던 Monolythic 시스템과 별반 차이없는 괴물이 되어버린다. Monolythic 구조의 문제점을 해결하는데 적절한 대안으로 마이크로서비스 구조가 딱이긴 하다. 하지만 과하면 탈이 나긴 마련인데… 이 상황을 다른 각도에서 볼 여지는 없을까?

지금까지의 논의에서 작은 시스템이 많아졌을 때 이런 문제 저런 문제라고 이야기를 했지만 그 본질은 “연동”에 있다. 연동을 위한 관리 포인트, 직렬화된 순차적 연동, 연동의 깊이에 따른 문제 진단의 어려움! 그렇다 문제는 바로 연동이다!!
그럼 이 시점에서 연동을 왜 하는지를 생각해보자. 연동의 목적의 기능(Function)에 있는지 아니면 데이터 흐름(Flow)에 목적이 있는지? 후자의 경우라면 데이터 흐름을 제공하는 시스템이 있다면 문제를 좀 더 손쉽게 풀 수 있지 않을까? 서론이 무지 길었는데 이것이 하고 싶은 이야기다. (정말 말이 많은 편이다. ㅠㅠ)
System as a data perspective
넓은 의미에서 우리가 만드는 시스템은 데이터의 흐름이다. 외부 입력은 시스템에 내재된 로직의 계산 과정을 거친다. 시스템의 한 어플리케이션에서 처리된 데이터는 다른 어플리케이션으로 흐른다. 데이터의 흐름은 큰 맥락상 순차적이거나 혹은 확산적인 형태일 수 있다.
Consecutive data flow

순차적 데이터 전달 모델은 시스템은 입력을 이용해 결과물을 만든다. 한 어플리케이션의 출력은 다른 어플리케이션의 입력으로 이어진다. 크게 색다를 것도 없다. 대부분의 마이크로서비스가 가지는 전형적인 모델이다. 시스템의 전체 형상에서 필요한 로직을 코드로 반영했고, 안타깝게도 흐름 관련 부분도 개발자가 코드로 추가 제어를 해야만 한다.
우리의 업무 로직은 반드시 존재해야한다. 하지만 전체 데이터 흐름을 제어하는 것까지 꼭!!! 제어해야만하는 걸까? 그림에서 보이듯이 우리의 입력이 D API Service에 도달하면 그만이다. 흐름의 제어해줄 수 있는 존재가 있다면, 우리는 이 흐름만을 정의하면 된다. 그리고 흐름 사이에 새롭게 필요해진 업무 로직을 살짝 끼워넣는다. 기존에 잘 돌아가던 기능들을 변경하지 않는다.
- 새로운 로직을 Input/Output Data Format에 근거해서 만들면 된다.
- 그리고 이 로직을 흐름 사이에 반영하면 된다.
기능들을 조합하기 위해 별도의 시스템을 새로 만들 필요도 없고, 기존 시스템들을 변경시키지도 않는다.
Data proliferation
쓸모가 많은 데이터의 경우 많은 사람들/시스템들이 해당 데이터를 원한다. 데이터를 얻는 대부분의 방법은 구하는(Get) 것이다. 원하는 사람이 데이터를 구하는 것이지 원한다고 데이터를 가진 사람이 떠먹여주진 않는다. 그런데… 떠먹여주면 안될까???
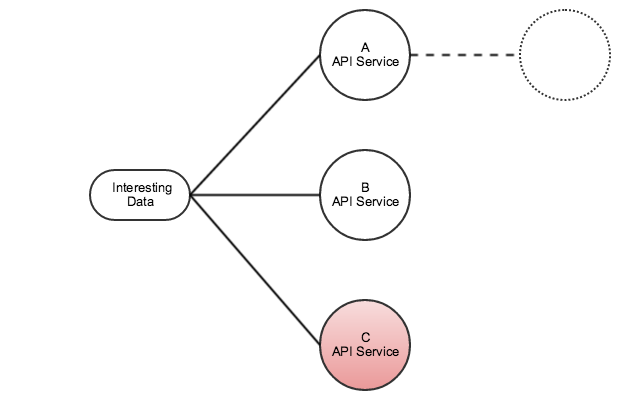
쓸모가 많은 데이터의 경우라면 관심 시스템들이 요청로직을 개별적으로 만드는 것보다는 아예 전달받는 데이터를 가진쪽에서 전달해주는 것이 훨씬 더 효율적일 수 있다. 특히 관심 데이터가 생성(Available)되었을 때 이를 전달자가 즉시 구하는 쪽에 바로 전달할 수 있다. 이는 시스템간의 데이터 동시성을 보장한다는 큰 매력이 된다. 이외에 데이터를 가진 쪽에서 바로 데이터를 넣어주기 때문에 구하는 쪽에서 일일히 Get(or Query) 기능을 구하지 않더라도 바로 들어오기 때문에 구현적 관점에서도 일부 이점을 제공한다. (하지만 크지는 않다 ㅠㅠ)
Kafka
Kafka는 오픈 소스 분산형 메시징 시스템이다. 주절이주절이 설명하는 것보다는 공식 홈페이지에 들어가보면 관련 내용을 잘 찾아볼 수 있다. 관련 책을 한권 사서 읽어도 봤지만 책보다는 그냥 홈페이지랑 구글링 통해서 얻는 자료가 더 유익하다. 그만큼 오픈 소스의 힘은 위대한 거겠지?
만든 사람들이 이야기하는 Kafka의 주요 능력이라고 개요 페이지에 적어둔걸 옮겨본다.
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
- It lets you store streams of records in a fault-tolerant way.
- It lets you process streams of records as they occur.
정리해보면 Publish & Subscribe 모델을 지원하는 메시징 시스템이고, 분산형 시스템들이 가지는 대부분의 특징처럼 한 두개 장비가 망가지더라도 잘 돌아간다라는 것, 그리고 Queue를 기본한 메시징 시스템으로 데이터 순서를 보장한다라는 것이다. 개인적인 매력을 느끼는 부분들을 열거해보면…
- 시스템이 별도의 DB등 번거로운 외부 시스템을 필요로 하지 않는다. DB. 정말 싫다.
- 설치할게 별로 없다. 압축풀고 실행시키면 바로 돈다.
- 특이한 프로토콜을 사용하도록 강요하지 않는다. Producing/Consuming 과정에서 String 혹은 Byte Array를 바로 사용할 수 있다. 정 특이한걸 만들고 싶으면 역시나 만들어서 쓸 수 있다.
가장 잘 적용되리라고 생각되는 분야는 real-time streaming data pipeline 이다. 실시간 데이터의 시스템/어플리케이션간 손실없는 전달이 필요한 환경에 최적이다라고 개발자들이 이야기하고 많이 써보지는 않았지만 동감한다.
Why Kafka?
왜 그럼 이 시스템을 구현하는데 Kafka를 선택했을까?
- 빠르다 – 분산형 메시지 처리와 관련된 시스템들이 Kafka 이전에도 Active MQ와 같이 다양하게 존재해왔다. 이런 분산형 시스템들에 비해서 Kafka 시스템이 갖는 강점은 빠른 데이터 처리에 있다. 여러 이유가 있을 수 있겠지만, Kafka를 최초로 개발한 LinkedIn 팀에서 기존 Messaging system의 문제점을 분석하고 이를 개선하기 위해 어떤 부분이 시스템의 핵심이 되어야하는지, 그 맥락을 잘 집었다고 볼 수 있겠다.
- Publish & Subscribe 모델 지원 – 앞서 언급한 데이터 활용 모델을 구현하기 위해서는 메시징 시스템이 Publish & Subscribe 모델을 지원해주는게 최선이다. 지원하지 않는다면 따로 이 부분을 구현해야하는데 데이터의 연속성 보장등을 어플리케이션에서 단독으로 보장하기에는 많은 무리수가 있다. Topic을 기반으로 Kafka가 이 부분에 대한 강력한 뒷배경이 되어준다.
- 잠깐 다운되도 된다 – 데이터를 처리하는 Consuming 시스템의 입장에서 다운타임은 운영적 관점에서 치명적인 시간이된다. 하지만 Kafka 역시 분산형 메시지 시스템들이 공통적으로 지원하는 메시지 보관 기능을 마찬가지로 지원한다. 다만 언제까지고 데이터를 보관해주지는 않는다. 시스템 단위에서 설정된 보관 시간이 존재하고, 해당 시간 이내의 데이터는 분산환경내에 보관된다.
Topic and Partitions
본격적인 이야기를 진행하기전에 Kafka 내부에서 데이터가 다뤄지는 Topic과 Partition에 대한 개념에 대해 짧게 알아보고 가자.
Topic은 Kafka에서 데이터에 대한 논리적인 이름이다. Kafka를 통해 유통되는 모든 데이터는 Topic이라는 데이터 유형으로 만들어지며 Producer/Consumer들은 자신이 생성 혹은 소비할 Topic의 이름을 알고 있어야만 한다.
Partition은 Topic을 물리적으로 몇 개의 분할된 Queue 형태로 나눠 관리할지를 지정한다. 특정 Topic이 1개의 Partition으로 되어 있다는 것은 데이터 처리를 위한 Queue가 한개 존재한다는 것이다. 3개의 Partition으로 구성되어 있다면 3개의 Queue가 존재하고, 각각의 Queue에는 독립적으로 데이터가 들어갈 수 있다. 이론적으로 Partition의 개수가 많을수록 동시에 클러스터에 데이터를 더 빠르게 받아들일 수 있음을 의미한다. 하지만 과하면 망한다는거… 따라서 클러스터를 구성하는 서버, CPU/Core, Memory 등 Resource의 제약을 고려해서 최적의 Partition 정책을 세우는게 필요하다.
우리가 다루는 Kafka내의 메시지/데이터는 모두 Topic이라는 이름을 통해 유통된다. 그리고 이 유통 과정에서 성능이 제대로 나게 할려면 시스템에 걸맞는 Topic별 Partition 정책을 어떻게 가져가야할지를 잘 판단해서 결정하는게 필요하다!
Messaging system with Kafka
자 여기까지를 바탕으로 Kafka를 이용한 메시징 시스템 구현 내용을 본격적으로 탐구 생활해본다.
지금까지 Kafka 시스템에 대해 쭉~ 이야기했다. 계속 이야기를 했지만 Kafka 자체가 메시징 시스템이다. 그런데 여기다가 뭘 더할게 있다고 이야기를 더할려고 할까? 메시지 시스템은 다른 시스템이 쓰라고 존재한다. 그렇다면 관건은 이 시스템을 어떻게 하면 손쉽게 사용할 수 있을지다. 아무리 좋다고 하더라도 사용하기 불편하다면 말짱 도루묵이다. 결국 시스템이 사용하는 시스템이더라도 그 시스템을 사용하도록 만드는건 사람이고, 복잡한 절차나 기술적인 난해함이 있다면 환영받지 못한다.
환영받는 메시지 시스템이 될려면 어떤게 필요할까?
- 접근성이 좋아야 한다. 개발자라면 누구나 아는 기술로 접근이 가능해야 한다.
- 표현의 자유를 보장해야 한다. 메시지에 어떤 데이터가 담길지 나도 모르고 당신도 모른다. 그런고로 다양한 데이터 형식을 기술할 수 있는 자유도를 가지고 있어야 한다.
사실 Kafka가 좋긴 하지만 이걸 사용하는 사람이 굳이 Kafka를 이해하면서까지 이 시스템을 쓰라고 하는건 어불성설이다. 따라서 메시지 시스템의 내부는 감추면서 개발자들이 보편적으로 활용할 수 있는 기술들을 가지고 접근할 수 있도록 해주는게 가장 좋다고 생각한다.
이런 특성들을 고민해봤을 때 가장 좋은 것은 Publish & Subscribe 구조에 대응하는 Producer / Consumer를 연동하는 개별 어플리케이션이 Kafka 수준에서 연동하도록 할게 아니라 이를 중계해주는 Delegating Layer를 지원해주는게 좀 더 효과적이다. Delegating Layer를 통해 Kafka에 대한 의존성 대신 흔히 어플리케이션 연동을 위해 사용하는 HTTP 프로토콜을 사용할 수 있도록 한다면, 연동하는 어플리케이션들이 보다 손쉽게 이를 이용할 수 있다. 또한 JSON 메시지를 활용하면 앞서 이야기했던 표현의 자유를 적극적으로 챙길 수 있다. 물론 개발자들의 익숙함은 덤일 것 이고 말이다. 설명한 전체적인 윤곽을 간단히 스케치해보면 아래와 같은 형상이 될 수 있다.

- Producer – HTTP POST 방식으로 연동 어플리케이션으로부터 Payload 값을 받는다. Payload가 Kafka 시스템을 통해 유통될 Topic의 이름은 URI Path Variable을 통해 전달받는다. RESTful의 개념상 Path Variable이 자원의 이름을 내포하기 때문에 이 형태가 가장 적절한 표현 방법일 것 같다. POST 메소드를 사용하는 것도 메시지를 생성(Create)한다는 의미이기 때문에 맥락상 어울린다.
- Consumer – Kafka의 특정 Topic을 Subscribe하고 있으며, 생성된 데이터를 수신하면 이를 요청한 어플리케이션에 마찬가지로 POST로 JSON Document를 POST 메소드의 Payload로 전달한다. 여기에서는 POST 메소드로 전달 메소드를 전체적인 일관성을 위해 고정해서 사용한다. PUT 혹은 PATCH 등과 같은 다른 메소드를 사용할 수 있도록 허용할 수도 있으나 되려 이용에 혼선을 줄 수 있기 때문에 하나만 지원한다.
이와 같은 구조는 데이터를 생산/소비하는 쪽 모두에게 웹서비스의 기본적인 개념만 있다면 누구나 손쉽게 데이터를 접근할 수 있는 길을 열어준다. 생산자 측에서는 Producer의 endpoint로 JSON Payload로 데이터를 전달하면 된다. 소비자도 마찬가지로 JSON Payload를 받을 수 있는 endpoint를 웹어플리케이션의 형태로 만들어두면, 자신이 관심을 둔 메시지가 생성될 때마다 이를 수신하게 된다.
한가지 눈여겨 볼 부분은 메시지 시스템의 Consumer와 실제 Consumer Application의 관계다. RESTful 기반의 웹 어플리케이션은 입력된 Payload를 이용해 일련의 처리를 수행하고, 그 결과를 요청자에게 반환한다. 그리고 앞서 Consecutive Data flow의 그림에서 설명했던 것처럼 반환된 Payload는 연속된 처리를 위한 입력으로 사용되는 경우가 많다. 이를 개발자적인 관점에서 살펴보자. 일종의 함수(Procedure가 아닌 Function) 호출과 아주 비슷한 모델 아닌가?
topicedMsg1 returnedMsg1 = consumer1.function1(initialTopicedMsg);
topicedMsg2 returnedMsg2 = consumer2.function1(returnedMsg1);
topicedMsg3 returnedMsg3 = consumer2.function1(returnedMsg2);
...
약간 억지로 끼워맞추기식이긴 하지만 Method Chain 비슷해보이지 않나?? -_-;; 중요한 점은 특정 Topic이 있다면 해당 Topic을 입력으로 받는 Consumer를 찾을 수 있다는 것이다. 그리고 그 Consumer에게 Topic의 메시지를 전달하면 그 Response Payload를 얻을 수 있다. 하지만 Response로부터 Payload가 어떤 Topic인지를 명시하는 것이 좀 까리하다.
물론 Response Header에 Custom Header를 정의하는 것도 방법일 수 있겠다. 하지만 이렇게 하는 경우에 이를 암묵적인 규약으로 개발자들에게 강요하는 것이고 더구나 명시성이 떨어진다. Consumer Application의 코드를 알기 전에는 Topic 값으로 어떤 것을 반환하는지 알기 어렵다. 이런 경우에 명시적으로 아예 Consumer Application의 정의에 반환되는 Payload에 대응하는 Topic의 이름이 뭔지를 명시하는 것이 오히려 바람직하다고 개인적으로 생각한다.
이 방식으로 Consumer와 Consumer Application간에 상호작용하는 예시를 순서도로 그려보면 아래와 같은 형상이 될 수 있다.
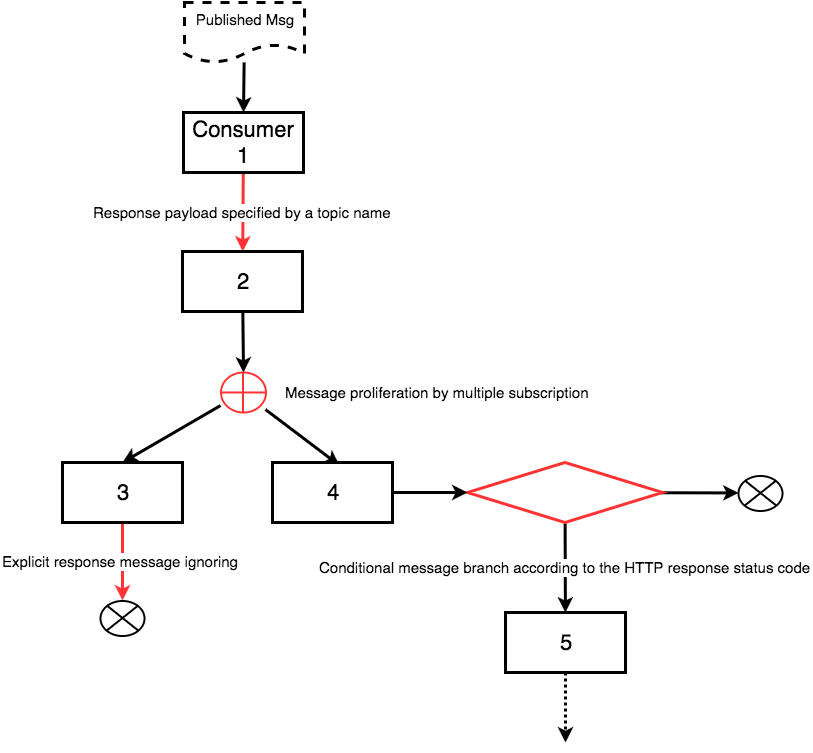
- 일반적인 경우는 Consumer 1과 같이 입력 메시지를 처리 후 Response Payload를 반환한다. Consumer 1이 반환한 Payload의 타입은 설정을 통해 어떤 Topic에 해당하는지 메시지 시스템은 알고 있다. 반환 메시지를 시스템에 지정된 Topic 이름으로 Publish함으로써, 자동적으로 다음 순서에 해당하는 Consumer 2를 찾아 들어가게 된다.
- 특정 Topic에 대해서는 여러 Consumer들이 관심이 있을 수 있고, 당연히 여러 Consumer에게 동시에 전달된다.
- Consumer Application에서 반환된 값이 무시되어야 할 경우도 있다. (물론 반환 Payload는 존재할 수 있다.) 이 경우를 위해 명시적으로 해당 Response Payload를 무시하기 위한 장치가 필요하다. 이미 우리는 프로그래밍 과정에서 void 라는 단어와 많이 익숙하다. Topic의 이름 가운데 void 라는 reserved keyword를 둔다. 그리고 Topic의 이름이 void인 경우에는 반환된 payload를 무시한다.
- 일괄적으로 메시지를 무시하는 경우가 아니라 특정 케이스에 한해서만 시스템이 이를 무시하도록 만들고 싶은 경우도 발생한다. 이건 코딩에서 if 문과 비슷한 역할이다. 이에 대한 처를 위해 HTTP Status code 가운데 특정 값을 Response 값으로 반환하는 경우에 Response Payload를 무시하도록 하자. HTTP Status code는 개발자들의 공통 사항이기, 별도의 장치를 두는 것보다는 훨씬 설득력이 있다. (이 경우가 필요할까 싶기도 하지만 실제로 활용하다보면 정말 많은 도움이 된다. 이게 있으면 메시지 시스템을 가지고 for loop도 만들 수 있다!!!)
시스템에 대한 이야기 와중에 이 부분의 이야기가 가장 길었다. 그만큼 메시징 시스템 가운데 개발을 해야하는 측면에서 가장 많은 시간 투자가 필요한 부분이다. 하지만 이 시나리오에 맞춰서 잘 만들어두면 정말 편리한 세상을 당신이 만들고 있다는걸 알게 될 것이다.
Pros
메시징 시스템을 중심으로 마이크로서비스 방식의 어플리케이션 시스템을 구성한다고 했을 때 다음과 같은 이점을 기대할 수 있다.
- 서로 의존성이 없는 작업들을 동시에 처리할 수 있다. 시스템 수준의 상당한 성능 향상을 기대해 볼 수 있다.
- 단위 작업에 집중할 수 있다. 작업/배포의 단위를 더욱 더 작게 만들 수 있다. 노드 혹은 go 언어가 더 득세할 수 있지 않을까?
- 설정 변경만으로 새로운 업무 처리가 가능하던가 혹은 기존 업무 흐름을 손쉽게 조작할 수 있다.
- 데이터를 주고 받아야 할 상대방의 endpoint를 굳이 알 필요도 없고, 상대방을 직접 호출할 필요도 없다.
Cons
메시징 시스템이 많은 장점을 주는 것처럼 보이지만, 이것도 실제로 쓸려고 했을 때 이런 저런 문제점이 있다.
- 시스템 자체가 문제다. 구축을 위해서는 Kafka 및 Producer/Consumer 클러스터를 구축하는데 상당히 시간이 걸린다. 장기적이 아니라면 그냥 일반적인 마이크로서비스 체계를 구축해서 사용하는게 훨 낫다.
- 트랙잭션 이런걸 생각하지말자. SOA로부터 현재의 마이크로서비스 세상까지 웹 도메인에서 트랜잭션을 완성시키고자하는 많은 노력이 있었다. 하지만 제대로 된 놈을 못봤다. 마찬가지로 여기에서도 이걸 실현시킬 생각을 했다면 번지수를 한참 잘못 찾았다. 되려 트랜잭션이 없어도 돌아가도록 본인의 어플리케이션을 설계하는게 훨씬 더 재미있을 것 같다.
- 비동기 방식이다. 성능적으로는 아주 좋은 이점이지만 실제 운영될 때 상상을 초월하는 모습을 보여주는 경우가 있다. 특히 타이밍이 맞아야 하는, 즉 동기성이 필요한 부분에 이 시스템을 이용한다면 낭패를 볼 수 있다. “내가 확인했을 때 항상 그랬다!!” 라는 말을 비동기 세상에서는 하지 말자. 항상 그렇게 동작하다 중요한 순간에 당신을 배반하는게 비동기 세상이다.
여기까지다. 이 과정을 통해 만들었던 시스템이 궁극의 마이크로화를 향해나가는 서비스 세상에서 서로 얽히고 설킨 거미줄 같은 실타래를 큰 파이프를 꼽아서 정리하는데 도움이 됐으면 좋겠다. 또한 동기적 세상에서만 머무리던 사고를 비동기를 활용할 수 있는 다른 기회의 세상이 되기를 또한 바란다.
이제부터는 Kafka 클러스터를 실제로 설치하는 과정에서 참고했던 정보와 주의해야할 몇가지 경험들을 공유하기로 하겠다.
Tips in building a Kafka cluster
기본 설치 방법: http://kafka.apache.org/quickstart 로컬 환경에서 간단히 돌려보기 위한 방법은 이걸로 충분하다.
AWS EC2 setup
물리 장비를 사용한다면 각 장비를 셋업해야하지만… 요즘 다 AWS 쓰는거 아닌가??? 그러니 AWS를 기반으로 설명하도록 하겠다.
- Kafka를 1개 instance로 셋업한다.
- 셋업된 instance를 AMI로 만들고, instance를 재생성할 때 이를 활용하면 좋다.
- 생성시킬 전체 클러스터의 각 EC2 instance의 IP를 DNS 작업을 해준다. 설마 IP로 관리할 생각을 가지고 있지는 않다고 생각하는데.
Configuring cluster
- 클러스터링: http://epicdevs.com/20 해당 사이트에서 기본적인 설치 방법에 대해 잘 설명해뒀다.
- Cluster 노드 장비들은 클러스터 외부에서 인식 가능한 이름을 부여하고 이를 DNS에 등록해서 활용하는게 좋다. 만약 DNS 등록이 여의치않다면 각 노드들의 이름을 개별 노드의 hosts 파일에 모두 등록하는 작업을 최소한 해둬야한다.
Possible issues
진행을 하다가 이런 문제점을 만날 수 있다.
Partition offset exception
kafka.common.KafkaException: Should not set log end offset on partition [test,0]'s local replica 2
at kafka.cluster.Replica.logEndOffset_$eq(Replica.scala:66)
at kafka.cluster.Replica.updateLogReadResult(Replica.scala:53)
at kafka.cluster.Partition.updateReplicaLogReadResult(Partition.scala:239)
at kafka.server.ReplicaManager$$anonfun$updateFollowerLogReadResults$2.apply(ReplicaManager.scala:905)
여러 이유가 있을 수 있지만, FAQ를 읽어보면 좋은 Insight를 얻을 수 있다. 내 경우에는 topic을 생성할 때 쉽게 하자고 현재 zookeeper 호스트의 이름을 localhost로 줬다. 이 때문에 cluster내의 다른 instance에서 해당 호스트를 제대로 찾아내지 못했던 것 같다. 이 경우에 topic자체는 생성된 것이기 때문에 전체 instance를 내렸다가 올리면 문제를 해결할 수 있다. 할려면 제대로 된 호스트 이름을 주고 작업해주는게 좋다.
Metadata error
기본 설정이라면 클러스터 환경에서Producer/Consumer client에서 Metadata를 확인할 수 없는 경우 아래와 같은 오류를 만날 수 있다.
2016-11-23 09:12:18.231 WARN 3694 --- [ad | producer-1] org.apache.kafka.clients.NetworkClient : Error while fetching metadata with correlation id 168 : {test=LEADER_NOT_AVAILABLE}
2016-11-23 09:12:18.334 WARN 3694 --- [ad | producer-1] org.apache.kafka.clients.NetworkClient : Error while fetching metadata with correlation id 169 : {test=LEADER_NOT_AVAILABLE}
오류가 발생하는 이유는 클러스터 외부의 장비에서 접속한 클러스터 장비 가운데 하나를 찾질 못해서 발생한다. 문제를 해결할려면 다음의 설정을 server.properties 파일에 반영해줘야 한다.
advertised.host.name = known.host.name
advertised.host.name 필드는 Broker에 접근한 클라이언트에게 “이 서버로 접근하세요” 라는 정보를 알려주는 역할을 담당한다. 별도로 설정을 잡지 않으면 localhost 혹은 장비의 이름이 반환된다. Producer 혹은 Consumer쪽에서 반환된 hostname을 인식할 수 없으면 추가적인 작업을 할 수 없으므로 이 오류가 발생된다. 따라서 해당 속성의 값에 DNS에 등록된 호스트의 이름을 넣어주거나 클러스터내에 존재하는 장비들을 클라이언트 환경의 /etc/hosts 파일에 반영해줘야 한다.
Amazon Kinesis
Kafka를 가지고 작업을 하다보니 아마존에서 재미있는 걸 만들었다라는걸 알았다. 키네시스(Kinesis)? 대강 살펴보니 하는 짓이 내가 지금까지 이야기했던 것들과 상당히 유사한 일을 해준다. 물론 아마존 클라우드에 있는 여타 기능들과의 연계성도 아주 좋다. 만약 장기적인 관점에서 Kafka 클러스터를 구축할게 아니라면 Kinesis도 다른 대안이 될 수 있을 것 같다.
특히 이 글을 읽는 여러분들의 시스템이 AWS에서 동작하는 것들이 많다면 Kinesis가 상대적으로 더 좋은 선택이 될 수 있다. 가끔 생각지도 않은 요금 폭탄에 대해 쓰기전에 고민은 반드시 필수다!!




 바쁘게 개발 작업을 하면서 “마이크로서비스 아키텍처 방식으로 개발한다” 라는 것을 올바르게 실행하고 있는지 의문이 들었다.
바쁘게 개발 작업을 하면서 “마이크로서비스 아키텍처 방식으로 개발한다” 라는 것을 올바르게 실행하고 있는지 의문이 들었다. 업무의 가시성과 관련된 세션도 있었는데, 흥미로운 점은 이제 다들 에자일 혹은 XP 이야기를 굳이 세션에서 꺼내지 않는다는 점이다. 어떤 세션에서는 강연자가 “나는 에자일을 싫어한다” 라고 이야기를 해서 객석에 있는 사람들로부터 환호성을 받기도 했다. “이건 뭐지???” 라는 생각이 휙 머리를 스쳤다. 하지만 그 친구가 이야기하는 것 자체가 이미 에자일스러웠다. 반어적인 것 같지만 그만큼 유연하게 업무를 진행하는 방식은 이미 일상화가 됐다고 보여진다. 청중의 환호는 강제적인 에자일 “프로세스의 실행 강요”에 대한 이질감의 표현이지 않을까 싶었다. 자꾸 틀이라는 것을 강조하는 구태적인 사고는 필요없을 것 같다. 자유로운 개발을 위해 필요한 것들만 취하면되지 형식이 있다고 굳이 거기에 몸을 맞출 필요는 없다.
업무의 가시성과 관련된 세션도 있었는데, 흥미로운 점은 이제 다들 에자일 혹은 XP 이야기를 굳이 세션에서 꺼내지 않는다는 점이다. 어떤 세션에서는 강연자가 “나는 에자일을 싫어한다” 라고 이야기를 해서 객석에 있는 사람들로부터 환호성을 받기도 했다. “이건 뭐지???” 라는 생각이 휙 머리를 스쳤다. 하지만 그 친구가 이야기하는 것 자체가 이미 에자일스러웠다. 반어적인 것 같지만 그만큼 유연하게 업무를 진행하는 방식은 이미 일상화가 됐다고 보여진다. 청중의 환호는 강제적인 에자일 “프로세스의 실행 강요”에 대한 이질감의 표현이지 않을까 싶었다. 자꾸 틀이라는 것을 강조하는 구태적인 사고는 필요없을 것 같다. 자유로운 개발을 위해 필요한 것들만 취하면되지 형식이 있다고 굳이 거기에 몸을 맞출 필요는 없다. 프로그래밍 언어적인 측면에서 자바는 계속 살아남기 위해 분투중이었다. 하지만 마이크로서비스 분산 환경에서의 대세는 아마도 Go 언어인 것 같다. 어떤 언어가
프로그래밍 언어적인 측면에서 자바는 계속 살아남기 위해 분투중이었다. 하지만 마이크로서비스 분산 환경에서의 대세는 아마도 Go 언어인 것 같다. 어떤 언어가