Spring framework에서도 5.X 버전부터 Reactive 방식의 프로그래밍이 가능하다. 이게 한 1년 이상 전 이야기인 것 같다. 내 입장에서 좋기는 한데 이게 그림의 떡이었다. 대부분의 Java Backend 개발을 Springboot framework을 가지고 하고 있는데, 여기에 Spring framework만 5.X 버전으로 덜렁 넣을 수 없기 때문이다. Spring 5.X 버전을 지원하기 위해 2.X 버전이 개발중에 있었지만, Milestone 버전이었고, 옆에서 Early Adopter 기질을 가진 친구가 고생하는 모습을 보니 아직은 때가 아닌 것 같았다. 아직은 스프링부트 1.X 버전이나 잘 쓰자 생각했다.
한 반년 사이에 Springboot 2.X 정식 버전이 릴리즈됐다. 하지만 바쁘다는, 2.X 버전으로 부트 버전만 변경하는게 별 의미없다는 핑계들을 가져다대며 미적댔다. 그 사이에 다른 친구들은 프로젝트에 Spring Reactive를 Streaming 방식으로 적용해서 성공적으로 마무리를 시켰다. 사람들에게 이제 Reactive의 시대니까 백엔드도 이 방식으로 개발을 해야한다고 떠들고 다녔다. 어이없게도 정작 내가 개념을 입으로만 떠들고 아는체하고 있는게 아닌가? 가장 싫어하는 짓을 내가 하고 있으면서 그걸 모른체하고 있다는게 어이없긴 하다.
출장중에 잠못드는 밤이 많고, 그 시간에 꾸역꾸역 억지로 잠을 청하느니 차라리 밀린 숙제나 해야겠다라는 심정으로 자료를 찾아봤다. 간단한 몇번의 구글링만으로도 뭔가를 시작해볼 수 있는 자료가 화면을 가득 채운다. 나만의 썰 몇 가지를 주절여보고, 검색 결과로 나온 아주 괜찮은 몇가지를 추려봤다.
Reactive Programming의 개념부터 정리해보자.
단어적인 의미를 직역하면 “반응형” 프로그래밍이다. 반응한다라는 것으로 어떤 의미일까? 주체적으로 동작하는 것이 아니라 외부 요인에 의해서 동작이 실행된다라는 것을 의미한다. Frontend 환경에서는 이런 반응형 프로그램이 ReactJS와 같은 Javascript framework의 발전과 더불어 보편적으로 채택되고 있다. UI 환경의 동작을 실행시키는 주된 요인은 사용자의 키보드 입력 혹은 마우스 클릭과 같은 이벤트와 Backend 서버에서 보낸 데이터의 “도착” 같은 것들이 대표적이다. 이런 요인들을 Browser 혹은 Framework이 Event/Promise와 같은 형태로 Trigger 시키고, 이를 Listening하는 개발자의 코드가 실행되는 모델이다.
Backend 환경은 User event와 같은 것들이 없다. 다만 IO를 중심으로 데이터가 “반응”을 촉발시키는 매체가 된다. Synchronous 환경은 직렬화된 데이터 처리를 강요한다. 반응형이 될려면 당연히 Asynchronous IO 기반의 데이터 처리가 기본이 되어야 한다. 사실 컴퓨터라는 것 자체가 Asynchronous하게 동작되는 물건인데, 개발자가 편하라고 Synchrnonous progrocessing을 지원했던 건데 세월이 지나보니 다시 과거의 개념으로 회귀한 것이다. 뭐 물론 다른 차원의 이야기이지만.
스프링의 언어 기반인 자바는 최초에 Synchronous IO만 지원했다. 그러다 Java 1.4 시점에 NIO라는 컨셉으로 Asynchronous IO를 지원하기 시작했다. 내가 Open Manager 2.0 버전을 설계하던 즈음에 이거 나온거보고 이거다 싶어서 작업을 했던 기억이 아련하다. Async IO의 장점은 데이터를 읽어들이는데 있다. Sync IO의 경우 자신이 지정한 데이터가 도착할때까지 무작정 기다려야한다. 반면에 Async는 데이터가 도착했는지를 확인하고, 도착하지 않았다면 그 사이에 다른 작업을 수행하면 된다. 원래 IO 처리 대상이 되는 socket은 Duplex Channel 방식을 지원한다. 즉 한 socket의 FD값을 알면, 두 개 이상의 쓰레드에서 읽고, 쓰기를 동시에 할 수 있다. 그리고 Async IO는 이와 같은 duplex channel 방식의 통신이 지원되는 기반에서 동작한다.
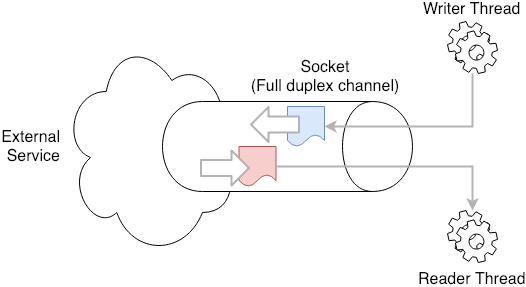
통상 이런 일련의 흐름을 개발자가 모두 코딩하기 어렵다. 그래서 필요한 것이 일종의 엔진이다. 엔진은 데이터가 도착했는지 확인하고, 도착한 데이터를 요청한 대상(Subscriber or Listener)에게 데이터를 넘겨 처리한다. 간단히 설명했지만, 이를 실제로 동작하게 하기 위해 Thread Pool, Queue, Publish and Subscribe 등이 기본적으로 갖춰져야한다.(2004년에 이걸 다 처음부터 끝까지 구현했다라는게 놀랍기는 하다.)
Spring framework 5.0 / Springboot 2.0 버전은 위와 같은 실행 모델을 지원하기 위한 전체 틀을 지원한다. 여기에는 실제 작업을 수행하는 Web Controller 수준의 작업 정의(Get/Post/Put… Mapper)와 내부의 데이터 수행을 위한 Mono/Flux와 같은 이벤트 방식의 실행 모델 및 이를 지원하기 위한 API 집합등을 포함한다. 또한 기반 웹서버와의 통합도 아주 중요하다.
Servlet이 특정 쓰레드에 의해 단독으로 처리되는 방식이 아닌 이벤트 방식으로 동작되어야 최적의 성능을 낼 수 있기 때문이다. 때문에 Netty를 쓰라고 권고하는 것이고, 톰캣은 너무 덩치가 커서 이 방식으로 전환하기에는 적절하지 않아서 동작되도록만 맞추고 최적화는 Give Up 한 것으로 보인다.
Googling…
기초 개념을 알면 이제 뭘 해야할까? 개발자라면 가끔씩 무턱대고 코드를 짜보는 것도 나쁘지는 않다. 그래도 무작정하는 것보다는 잘 파악한다음에 하는 성격을 가진 분들도 있다. 그런 분들에게 도움이 될지 모르겠지만 찾아본 자료들 가운데 Wow 했던 자료들 몇개를 링크한다.
- Servlet or Reactive Stacks: The Choice is Yours. Oh No… The Choice is Mine! – Rossen Stoyanchev – 2017년 SpringOne 발표된 자료인데, 시류가 Reactive라고 무조건 MVC(Sync)를 버리고 Reactive 방식을 따르지 말라고 충고한다. Pivotal에서 Reactive를 밀고 있는 사람인데 약파는 말이 아니라 쓰는 사람 관점에서 이야기를 한다. Awesome!! 물론 더 다양한 팁과 사례도 소개된다. 1시간 10분 남짓 분량인데, 조곤조곤 이야기를 설명을 참 잘한다.
- Web on Reactive Stack – 스프링쪽에서 만든 WebFlux의 How-To 문서이다. Spring MVC 모델에 대한 개념이 있다면, 이 문서를 읽어보는 것만으로도 뛰어다닐 수 있을 것이다.
- Mono and/or Flux – Spring Reactive Programming을 하기 위해 제공되는 객체 모델은 Mono와 Flux로 나뉜다. 이름이 의미하듯이 Mono는 1회성 데이터의 Reactive model을 위해 사용되고, Flux는 Streaming 방식의 Reactive Model을 위해 사용된다. Javadoc 문서인줄 알았는데, 비동기적 데이터의 흐름이 어떻게 되는지 제공되는 method 별로 그림을 곁들여 아주 잘 설명하고 있다. 읽어보는 것만으로도 개념을 이해하는데 많은 도움이 된다.
- Which operator – Mono/Flux를 사용해서 개발을 하더라도 Fully Reactive하게 코드를 작성하는게 만만하지는 않다. 이미 Synchronous 환경에 생각이 굳어져있어서, 특정 상황에 어떤 method를 쓰는게 좋을지 까리까리한 경우가 종종 발생한다. 이럴 때 이 문서를 참고하면 상황별로 어떻게 Reactive task를 시작하는게 좋을지 혹은 병렬로 처리된 2개의 Reactive Task를 Merge 시킬지에 대한 아이디어를 얻을 수 있다.
Springboot 2.X에서 Reactive project setup
오래 해보지는 않았지만, 가장 좋은 설정 조합은 WebFlux만을 사용해서 프로젝트를 셋팅하는 것이다. 이렇게 결심했다면 다음의 설정으로 처음 시작을 해보는게 좋다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
물론 원한다면 spring-boot-starter-web artifact를 추가할 수 있다. 이려면 MVC 방식과 Reactive 방식 모두를 사용해서 코드 작업을 해볼 수 있다. 단점은 MVC 방식이 훨 쓉기 때문에 원래 할려고 했던 Reactive를 금새 포기하게 될거라는거. 이왕 할려면 맘을 독하게 먹는게 좋지 않을까? 한가지 덧붙힌다면 starter-web artifact를 사용하는 경우, 기반 어플리케이션 서버가 Tomcat 이라는 점. 위의 구글링한 결과 가운데 첫번째 동영상 링크를 봤다면 알겠지만, 톰캣은 Servlet 요청을 Synchronous 방식으로 구현했다. 돌려 말하면 요청의 시작부터 끝까지를 완전 Reactive 방식으로 처리가 안된다. WebFlux 단독으로 사용하면 Servlet 스펙을 Asynchronous하게 구현한 Netty가 기반 어플리케이션 서버가 된다. Full Async 혹은 Reactive 방식으로 구현이 가능하다. 물론 starter-web artifact를 사용하더라도 설정을 추가로 잡으면 Netty를 쓸 수 있다. 하지만 할거면 제대로 해보라는게 충고 아닌 충고다. 영역한 동물은 쉬운 길이 있으면 굳이 어려운 길을 고집하지 않고 쉬운 곳으로 방향을 잡기 마련이다.
Spring reactive programming에서 아래와 같은 2가지 실행 모델을 지원한다.
- Mono – 단일 값에 대한 처리
- Flux – 서로 독립적인 복수 값들을 처리. 스트리밍 방식으로 떼이터를 처리할 때 주로 사용한다. 스트리밍 방식의 개념은 대강 할지만 여기에서 썰을 풀정도는 아니라서 스킵!
설명을 위해 이제부터는 Mono를 가지고 계속 이야기를 하겠다. 그림과 같이 Mono는 Flow를 가진다. Reactive programming이란 우리는 흐르는 과정에서 실행되길 원하는 코드를 lambda를 거치게 만드는거다. That’s it. 간단히 보자면 간단하다. 약간 어려운 부분들이 있다면, 대강 아래 같은 것들이지 않을까 싶다.
- Mono가 가지는 Value object의 immutable refernece를 갖는다. 중요한 점은 reference가 immutable이라는거지 value object의 state(or value)는 변경 가능하다라는 점이다.
- map() 혹은 비슷한 함수를 사용해 다른 타입의 Value object를 만들었다면, 그 객체에 대한 새로운 Mono가 만들어지고, 새로운 흐름이 만들어진다. 대부분의 경우에는 하나의 흐름을 상대하기 때문에 굳이 이런저런 걱정을 할 필요는 없다. 그리고 다른 흐름이 생겼다고, 원래 있던 흐름을 어케 정리하거나 할 필요는 없다. 이게 쓰레드나 파일과 같이 시스템의 리소스를 잡아먹는 그런 어마무시한 놈들은 아니라서.
- 여러 Mono들의 값들을 한꺼번에 다뤄야하는 경우가 있다. Mono는 흐름이지 직접적인 실행은 쓰레드 풀에 있는 언놈일지도 모르는 쓰레드가 담당한다. 기대 결과를 기다리는 Mono들이 준비가 된 상태인지를 확인하고, 그 상황에서 우리가 지정한 function이 실행되기 위해 zip() 혹은 when()과 비슷한 기능들을 활용할 수 있다.
- Java 개발자들이 lambda를 좋아한다고 생각안해서 그런지 모르겠지만, BiFunction() 혹은 TriFunction() 같은걸 쓰는 경우가 종종 발생한다. 자바 언어가 Strong typed language이기 때문이라고 추측을 해보지만, 무식하게 생겼다라는 느낌을 지울 수 없다. Mono/Flux 클래스에서 지원하는 메소드들이 이런 것들을 많이 활용하기 때문에 어떤 방식으로 Lambda 함수를 받아서 처리하는지 사전에 알아두는게 좋다. 안그럼 좀 많이 헷갈린다.
가장 많이 등장하는 그림이 아래 그림과 같다. 흐름이 종료되지 않으면 계속 그 흐름 과정에서 객체는 살아있다. 그리고 다른 객체 타입으로 변환되어 만들어지면, 그 순간 새로운 모노가 만들어진다.
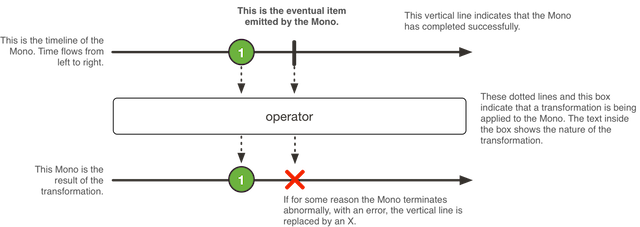
괜히 궁금해지는 부분! Mono 객체가 종료되지 않은 상태로 있다면 이 객체는 Garbage collection 대상이 되나? 이전의 테스트 상황에서 GC에 대한 부분을 구체적으로 살펴보지 않았지만 30분정도 부하 테스트에서 성능상 큰 문제가 없었던 것으로 봐서 GC 처리되는 것 같기는 하다. 최근에 하도 GC 문제 때문에 고생을 좀 해서 그런가 그래도 안전하게 할려면 안전한 종료 처리를 하는게 맞지 않을까 싶다.
이런 이해를 바탕으로 간단히 작업해본 셧다운(Shutdown) 로직 가운데 일부다.
@GetMapping("/{game}/{id}")
@ResponseStatus(HttpStatus.OK)
public Mono<PlayPermission> canPlayTheGame(@PathVariable String game, @PathVariable String id) {
return playerService.identifyPlayer(id)
.doOnSuccess(playerInfo -> ifFalse(gameService.isPlayableAge(game, playerInfo.calculateAge()), NotAvailableAgeResponseException.class))
.map((playerInfo) -> new PlayPermission(game, id, Permission.ALLOWED));
}
PlayerService에서 구현한 identifyPlayer는 WebClient를 통해 RESTful response를 받는다.
public Mono<PlayerAccount> identifyPlayer(String id) {
return webClient.get().uri("/api/v1/account/" + id)
.retrieve()
.onStatus(Predicate.isEqual(HttpStatus.NOT_FOUND), response -> Mono.error(new NotExistingPlayerResponseException(puuid)))
.bodyToMono(KasPlayerDto.class)
.map(kasInfo -> buildPlayerAccount(kasInfo));
}
So how about?
요 설정을 기반으로 했을 때 성능 테스트 결과를 얻었다.
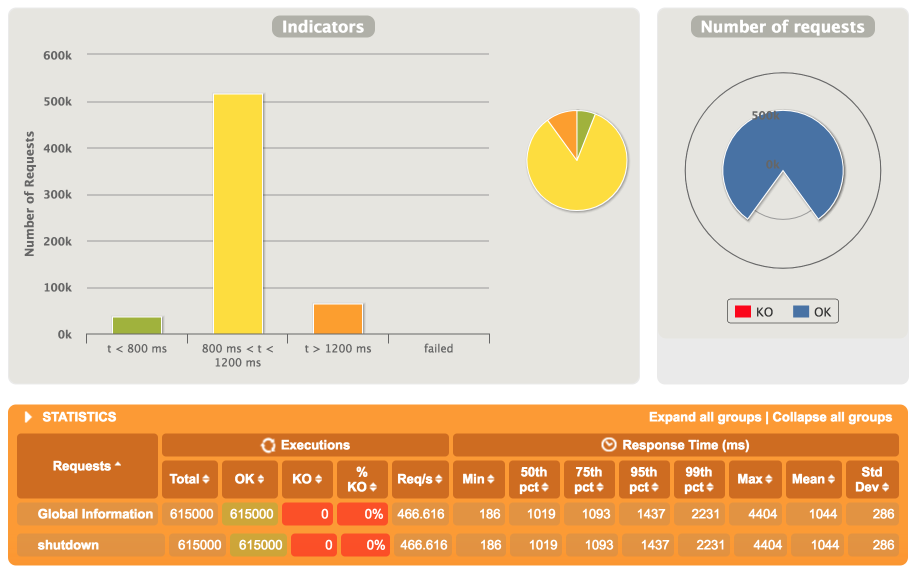
1000 Concurrent User를 m4.xlarge(4 Core, 8G Mem) 장비를 대상으로 실행했을 때, 466 TPS를 보였다. 재미있는 건 평균 응답 시간이 1초(1044 ms)다.
딱 곧이 곧대로 보자면, 4개의 Core로 처리할 수 있는 작업이 4개라는 이야기다. 음?
물론 곧이 곧대로 세상을 보지는 않을 것이다. 해당 Thread가 IO처리를 하면, 당연히 OS는 그 쓰레드를 Context Switching시키고, 다른 쓰레드를 CPU에 올려서 일을 시킬 것이다. 즉 처리량을 늘릴려면 쓰레드를 정량적으로 늘리면 된다. 하지만 일정 개수를 초과하는 쓰레드는 Context Switching 비용만을 증가실킬 뿐 효율성의 향상을 초래하지는 못한다.
여기에서 설명한 예제는 2개의 외부 연동 포인트를 가지고 있다. 첫번째는 회원 정보 연동을 위해 External Service를 RESTful endpoint로 요청하는 구간이고, 해당 계정 사용자가 해당 시간에 시스템에 접근하는 것을 허용할지 말지를 조회하기 위한 Repository 조회다. 각 단위 연동 시간이 아래와 같다고 하자.
- External RESTful query – 60ms
- Repository query – 20ms
이외 부차적인 JSON Serialization/Deserialization 등등을 위해 소모되는 시간까지 고려했을때, 총 소요 시간은 계산하기 쉽게 100ms라고 가정하자. Synchronous한 방법으로 Transaction이 처리된다고 가정하면 1개 Core에서 초당 수행 가능한 건수는 10건이다. 4개 Core라고 하면 단순 계산으로 40건을 처리할 수 있다.

헐… 근데 근데 부하 테스트 결과가 466 TPS라고? 사기아님?
![]()
사기라고 생각할 수 있지만, 위의 그림을 보면 납득이 될 것이다. 실제 어플리케이션의 쓰레드를 통해 실행되는 Code의 총 실행 시간은 20ms 밖에는 되질 않는다. 나머지 시간은 외부 시스템들(여기에서는 External Service와 Respository)에게 정보를 요청하고, 그 결과를 받는걸 기다리는 시간이다. 따라서 전체 CPU의 시간을 온전히 어플리케이션의 수행을 위해 사용한다면 50(1 core당 처리 가능한 Transaction 수) x 4 = 200개를 처리할 수 있다!
쉬운 이해를 위해 어플리케이션 자체 처리 시간을 20ms로 산정했지만, 실제 작성된 코드는 아름다운 최적화 알고리즘과 데이터 구조로 내부 처리 시간은 10ms안쪽에서 실행되기 때문에 466TPS 라는 숫자가 나올 수 있었다. 🙂
근데 MVC 방식으로 하든 Reactive 방식이든 정말 성능에 영향을 미치나? 당연히 미친다. 왜? 어떤 사람은 IO가 발생하면 쓰레드는 Context Switching되고, 다른 쓰레드가 CPU에 의해 실행되기 때문에 성능은 비슷해야하는거 아니냐고 반론은 제기할 수 있다. 틀린 말이기도 하고 올바르게 문제를 지적하기도 했다. 성능에 영향일 미치는 요인은 바로 Context Switching에 있다. Context Switching 자체도 결국 처리는 CPU에 의해 발생된다. 시스템이 CPU를 많이 잡아드시면 드실수록 사용자 프로세스(어플리케이션)이 CPU를 실제 일을 위해서 사용할 시간이 줄어든다. 바꿔말하면 열일할 수 없다.
Reactive 방식으로 열일 시킬려고 할 때 항상 주의해야할 부분이 있다. 바로 IO에 대한 처리다. IO 처리를 User code 관점에서 처리하면 안된다. 이러면 비용대비 효율성이 떨어진다. 이유는 IO에 대한 관리를 Reactive Framework에서 관리해줄 때 최고의 효과를 볼 수 있기 때문이다. User code 수준에서 IO에 대한 주도권을 가지면 IO 처리가 완료됐을 때 User code의 쓰레드가 이를 직접 제어해야한다.
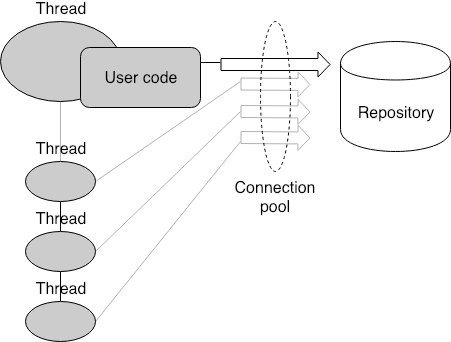
이 말은 쓰레드가 위의 그림에서처럼 기다려야한다는 의미이고, Context switching을 이용해야한다는 의미다. 그렇기 때문에 Reactive Framework에서 제공하는 WebClient 혹은 Reactive한 Repository들을 사용해야 한다.
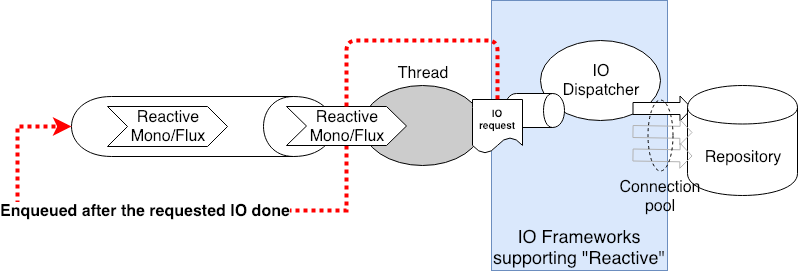
상상도이긴 하지만 실제 Reactive의 경우, 쓰레드의 Context에 의존하는게 아니라 각각의 Queue를 통해 User code의 control을 제어한다. 마찬가지로 IO에 대한 요청 역시 User code에서 이를 직접 제어하는 것이 아니라 Reactive Repository를 통해 필요한 데이터 Request를 위임한다. 그러면 IO Dispatcher 같은 놈이 데이터를 Connection Pool을 통해 실제 데이터 저장소 혹은 External Service에 전달한다. 이 과정에서 Async IO를 하기 때문에 굳이 Connection을 물고 기다리는 것이 아니라 계속 다른 요청을 전달한다. 물론 Connection Polling을 통해 특정 Connection에 응답이 도착하면 이를 관련된 Request에 Mapping하고 궁극적으로는 Mono/Flux 객체를 Reactive Queue에 넣어서 쓰레드가 어플리케이션 수준에서 다음 작업을 이어가게 한다. 이러한 이유로 RESTful Request를 처리하기 위해서는 Reactive에서는 RestTemplate이 아닌 WebClient를 사용해야 한다.
이 과정을 통해 시스템에 의한 개입을 최소화하여 어플리케이션 수준의 Performance를 극대화하는 것이 Reactive의 핵심이다.
Reactive programming에서 주의할 점들
일반적인 Sync 코딩 방법과는 달리 몇가지 부분들을 주의해야한다. 이 섹션은 앞으로 나도 작업을 하면서 보완해나갈 예정이다. 얼마나 잘 오류를 만들지에 따라 내용이 풍부해질지 아니면 빈약한 껍데기로 남을지는 모르겠다.
- 코딩 관점에서 반드시 생각할 점은 실행되는 쓰레드를 기다리게 만들면 안된다는 것이다. 로직을 실행하기 위해 필요한 데이터를 받아야 한다. RESTful API, NoSQL, MySQL이든 이건 IO를 통해 받기 마련이다. 이 과정에 Synchronous 한 부분이 들어간다면, 연산을 해야할 쓰레드가 불필요하게 대기해야한다. 이러면 Async 방식의 효율성이 크게 저하된다.
- 비슷한 맥락으로 Mono/Flux에서 지원하는 block() 함수도 실제 런타임 코드에서는 사용하지 말아야 한다. block() 함수는 연관된 Async 동작이 모두 완료될 때까지 현재 쓰레드를 마찬가지로 대기하게 만든다. 디버깅을 위해 한시적으로 사용하는 용도로는 가끔씩 사용할 수 있다.