Spring JPA는 데이터베이스를 사용하는데 있어서 새로운 장을 열었다. 쿼리를 직접 사용해서 데이터베이스를 엑세스하는 MyBatis의 찌질한 XML 덩어리를 코드에서 걷어냄으로써 코드 자체도 간결해지고 직관적으로 특정 Repository 및 DAO가 어떤 테이블과의 매핑 관계가 있는지를 명확하게 파악할 수 있도록 해준다. 단점으로 생각되는 부분이 여러 테이블들을 복잡한 조인 관계를 설정하는게 상당히 난감하다. 하지만 역설적으로 이런 조인 관계를 왜 설정해야하는지를 역으로 질문해볼 필요가 있다. 우리가 복잡한 코드를 최대한 단순화시키려고 노력할 때, 그 코드가 달성할려고 하는 목적과 의미를 가장 먼저 생각하는 것처럼. 더구나 마이크로서비스 아키텍처 개념에서는 한 서비스가 자신의 독립적인 Repository를 가지는 것이 원칙이라고 할 때 해당 Repository의 구조는 단순해야한다. 그렇기 때문에 Spring JPA가 더욱 더 각광을 받는 것이 아닐까 싶다.
AspectJ 역시 특정 POJO 객체의 값을 핸들링하거나 특정 동작을 대행하는데 있어서 아주 좋은 도구이다. 주로 특정 Signature 혹은 Annotation을 갖는 객체 혹은 메소드가 호출되는 경우에 일반적으로 처리해야할 작업들을 매번 명시적으로 처리하지 않아도 AspectJ를 통해 이를 공통적으로 실행시켜줄 수 있기 때문이다.
작업하는 코드에 이를 적용한 부분은 특정 DB 필드에 대한 자동 암호화이다. 값을 암호화해서 저장하고, 저장된 값을 읽어들여 평문으로 활용하는 경우가 있다. 이 경우에는 이만한 도구가 없다.
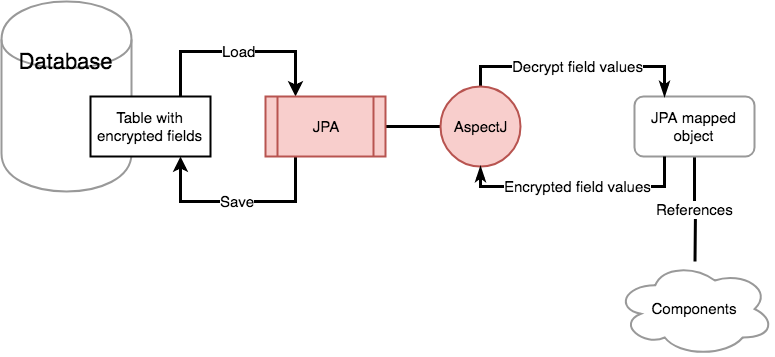
이런 이해를 바탕으로 지금까지 서비스들을 잘 만들어서 사용하고 있었다. 그런데 새로운 기능 하나를 추가하면서 이상한 문제점이 발생하기 시작했다. 암호화된 테이블에 대한 저장은 분명 한번 일어났는데, 엉뚱하게 다른 처리를 거치고 나면 암호화 필드가 저장되어야 할 필드에 엉뚱하게 평문이 저장되었다. 그전까지 암호화된 값이 잘 저장되었는데… 더 황당한 문제는 내가 명시적으로 저장하지 않은 데이터까지 덤탱이로 변경이 되버린다!!! 개별 기능을 테스트 코드를 가지고 확인했을 때는 이상이 없었는데, 개발 서버에 올리고 테스트할려니 이런 현상이 발생한다.
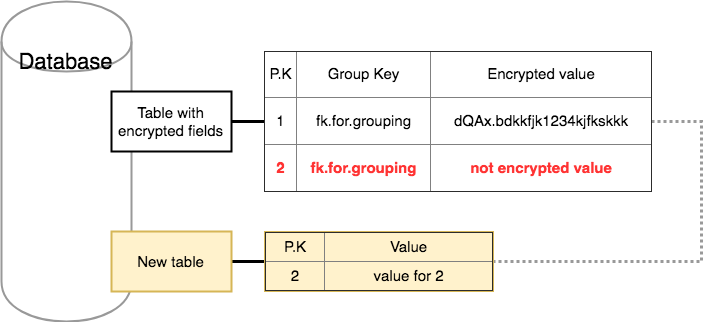
새로운 기능이 동작하는 방식을 간단히 정리하면 아래와 같다.
- 기존 테이블에서 2라는 키값이 존재하는 데이터를 쿼리한다. 원래 시나리오상으로는 이런 데이터가 존재하지 않아야 한다.
- 2라는 PK값을 가지는 데이터를 저장한다.
- 저장 후 fk.for.grouping 이라는 그룹 키를 가진 항목들을 로딩해서 특정 값을 계산한다. 읽어들인 걸 저장하지는 않고, 읽어들여서 계산만 한다.
- 계산된 결과를 신규 테이블(New table)에 저장한다.
디버깅을 통해 확인해보니 2번 단계에서는 정상적으로 AspectJ를 통해 암호화 필드가 정상적으로 저장된다. 그런데 4번 과정을 거치고나면 정말 웃기게도 평문값으로 업데이트가 이뤄진다. 그림에서 따로 적지는 않았지만, 멀쩡하게 암호화되어 있던 1번 데이터도 평문화되는게 아닌가??? 몇 번을 되짚어봐도 기존 테이블에 저장하는 로직은 없다. 뭐하는 시츄에이션이지??
JPA와 AspectJ를 사용하는데, 우리가 놓치고 있었던 점은 없었는지 곰곰히 생각해봤다. 생각해보니 JPA를 사용자 관점에서만 이해를 했지, 그 내부에서 어떻게 동작이 이뤄지는지를 잘 따져보지는 않았던 것 같다. 글 몇 개를 읽어보니 Spring의 Data JPA는 이런 방식으로 동작하는 것으로 정리된다.
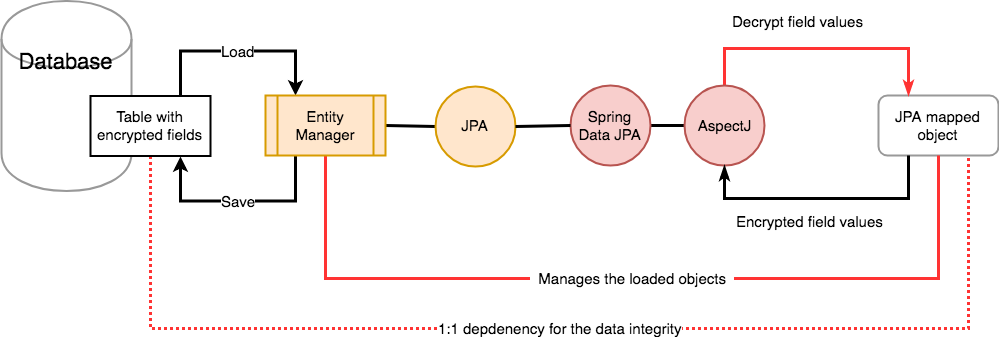
재미있는 몇가지 사실들을 정리하면 아래와 같다.
- RDBMS를 위한 Spring Data는 JPA를 Wrapping해서 그저 쓰기 좋은 형태로 Wrapping한 것이고, 실제 내부적인 동작은 JPA 자체로 동작한다.
- JPA는 내부적으로 EntityManager를 통해 RDBMS의 데이터를 어플리케이션에서 사용할 수 있도록 관리하는 역할을 한다.
- EntityManager는 어플리케이션의 메모리에 적제된 JPA Object를 버리지 않고, Cache의 형태로 관리한다!!!
EntityManager가 관리를 한다고?? 그럼 그 안에 있는 EntityManager는 어떤 방식으로 데이터를 관리하지?
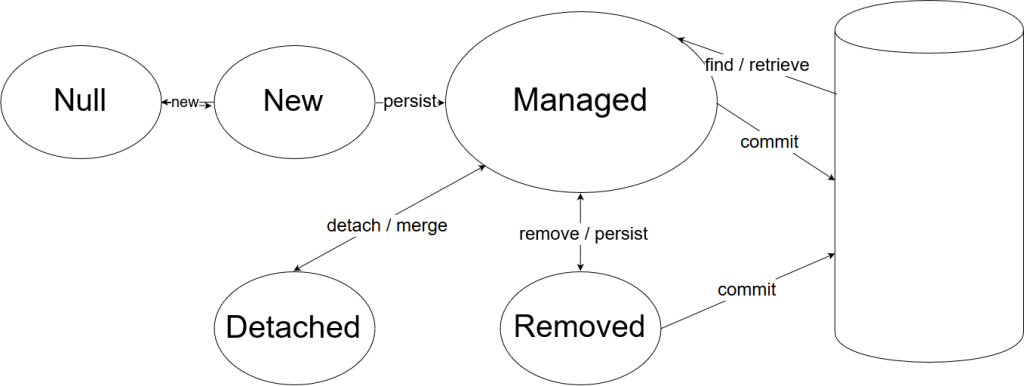
오호.. 문제의 원인을 이해할 수 있을 것 같다.
- Springboot application이 위의 처리 과정 3번에서 “fk.for.grouping 이라는 그룹 키를 가진 항목들을 로딩” 과정을 수행한다.
- 정말 읽어들이기만 했다면 문제가 없었겠지만 AspectJ를 통해서 읽어들인 객체의 암호화 필드를 Decryption했다.
- Entity Manager에서 관리하는 객체를 변경해버렸다! 객체의 상태가 Dirty 상태가 되버렸다.
- 4번 과정에서 신규 테이블에 데이터를 저장할 때, Entity Manager는 관리하는 데이터 객체 가운데 Dirty 객체들을 테이블과 동기화시키기 위해 저장해버렸다.
- 하지만 이 과정은 Entity Manager 내부 과정이기 때문에 따로 AspectJ가 실행해야할 scope를 당연히 따르지 않는다.
- 결과적으로 평문화된 값이 걍 데이터베이스에 저장되어버렸다.
따로 저장하라고 하지 않았음에도 불구하고 엉뚱하게 평문화된 값이 저장되는 원인을 찾았다.
문제를 해결하는 방법은 여러가지가 있을 수 있겠지만, 가장 간단한 방법으로 취한 건 이미 메모리상에 로드된 객체들을 깔끔하게 날려버리는 방법이다.
public interface DBRepositoryCustom {
void clearCache();
}
public class DBRepositoryImpl implements DBRepositoryCustom {
@PersistenceContext
private EntityManager em;
@Override
@Transactional
public void clearCache() {
em.clear();
}
}
위와 같이 하면 Spring Data JPA 기반으로 EntityManager를 Access할 수 있게 된다. 이걸 기존 JPA Interface와 연동하기 위해, Custom interface를 상속하도록 코드를 변경해주면 된다.
@Repository
public interface DBRepository extends CrudRepository<MemberInfo, Long>, DBRepositoryCustom {
...
}
여기에서 주의할 점은 DBRepository라는 Repository internface의 이름과 Custom, Impl이라는 Suffix rule을 반드시 지켜야 한다. 해당 규칙을 따르지 않으면 Spring에서 구현 클래스를 정상적으로 인식히지 못한다. 따라서 반드시 해당 이름 규칙을 지켜야 한다.
- DBInterface가 JPA Repository의 이름이라면
- DBInterfaceCustom 이라는 EntityManager 조작할 Interface의 이름을 주어야 하며
- DBInterfaceImpl 이라는 구현 클래스를 제공해야 한다.
이렇게 해서 위의 처리 단계 3번에서 객체를 로딩한 이후에 clearCache() 라는 메소드를 호출함으로써, EntityManager 내부에서 관리하는 객체를 Clear 시키고, 우리가 원하는 동작대로 움직이게 만들었다.
하지만 이건 정답은 아닌 것 같다. 제대로 할려면 AspectJ를 좀 더 정교하게 만드는 방법일 것 같다. 그러나 결론적으로 시간이 부족하다는 핑계로 기술 부채를 하나 더 만들었다.
참고자료
- https://www.javabullets.com/access-entitymanager-spring-data-jpa/
- https://www.javabullets.com/jpa-entity-lifecycle/
– 끝 –