개발자는 코드를 작성해야한다. 그리고 코드들이 엮이고 엮여 시스템이 만들어진다. 시스템은 필요를 요청한 사용자에게 기능을 제공한다. 물론 시스템을 구성하기 위해 필요한 노력을 개발자만 하는 건 아니다. 인프라 엔지니어는 장비와 네트워크를 준비하고, 데이터베이스 엔지니어는 데이터를 보관할 수 있는 저장소를 준비한다. 최근에는 Data Scientist가 데이터를 분석하고 빅데이터 도구를 통해 적절한 값들을 생성해낸다. 이외에도 다양한 노력들이 합쳐져 시스템이 만들어진다. 이것들을 아우리고 잘 버물려서 하나의 응집된 최종적인 기능으로 만들어내는 역할을 개발자가 담당한다. 그리고 코드는 이것들을 결합시키는 접착제이다.
코드는 여러 재료들을 잘 활용해 작성되야 한다. 어떤 재료의 쓰임이 과해지면 들인 것에 비해 제대로 된 시스템의 맛을 낼 수 없다. 음식을 하다보면 죽은 맛도 살려내는 것이 바로 MSG다. 라면 스프가 그렇고, 다시다가 그렇다. 기막힌 능력이다. 시스템을 만드는 과정에서도 MSG처럼 빠지지 않고 등장하는 재료가 있다. 바로 데이터베이스(DBMS)다.
데이터베이스란 뭔가? 간단히 이야기하면 데이터 저장소이고 시스템을 동작하는데 필요한 데이터를 저장하고 읽을 수 있는 기능을 제공한다. 데이터베이스 가운데 가장 개발자들이 선호도를 가진 것이 아마도 RDBMS이다. 가장 유명한 Oracle, MySQL, MS-SQL 등이 이 범주에 해당한다. 일반적인 경우라면 RDBMS를 빼고는 시스템을 이야기하기 어렵다.
그런데 왜 이걸 시스템 구축하는 MSG라고 이야기했을까? 데이터의 저장소일 뿐인데! 맞다, 모든 데이터베이스가 MSG 역할을 하는 건 물론 아니다. 개발자들이 주로 MSG로 사용하는건 RDBMS이다. 왜? 이유는….
RDBMS는 SQL이라는 언어를 사용해서 데이터를 처리한다. SQL이라는 언어는 C++나 Java와 마찬가지로 뛰어난 프로그래밍 언어다. 특히 데이터에 직접 접근하면서 이를 우리가 원하는 다양한 조건 혹은 형태로 추출해낼 수 있다는 건 개발자에게 아주 좋은 매력이다. 와중에 언어 자체가 아주 어렵지 않기 때문에 손쉽게 배우고 써 볼 수 있다.
만약 CSV 파일 형태로 데이터가 있다고 가정하자. 만약 즉시 사용할 수 있는 RDBMS가 있다면 이걸 쓰는 것이 가장 빠른 방법이다. 아무리 빠른 시간에 코딩을 한다고 하더라도 Java로 비슷한 코드를 작성하는 건 SQL늘 작성하는 것보다 훨 많은 시간과 노력이 필요하다. 하지만 기본적인 전제는 RDBMS가 있어야 한다는 사실. 하지만 있다면 정말 손쉽게 결과를 이끌어낼 수 있다.
이것처럼 있다면 손쉽게 것도 나이스하게 결과를 만들어낼 수 있다는 관점에서 RDBMS는 개발자에게 MSG다. 빠른 것만이 아니다. MSG가 일류 쉐프의 음식맛에 뒤지지 않는 맛을 만들어내는 것처럼 RDBMS를 뒷배경으로 깔면 좋은 성능의 시스템이 툭 튀어나온다. 많은 데이터를 효과적으로 다루기 위해 멀티 쓰레딩을 구현할 필요도 없고, 데이터 참조등을 위해 Hash Table을 구성할 필요도 없다. 심지어는 굳이 머리를 굴려 알고리즘을 생각해낼 필요도 없다. 이 모든걸 데이터베이스가 처리해준다. 그래서 RDBMS를 사용하는 서비스의 성능의 개떡같다면 DB 튜닝을 하면 완전 새로운 물건이 되기도 한다. 인덱스 혹은 쿼리 힌트(Query hint) 한 스푼이면 죽어가던 시스템이 당장 마라톤 풀 코스라도 뛸 정도의 스테미나를 발휘한다.
데이터베이스, 좋아~
데이터베이스가 이런 물건이라면 개발자들이 더욱 더 많이 써줘야 하지 않을까? 구글링을 통해 찾아낸 아래 SQL을 살펴보자.
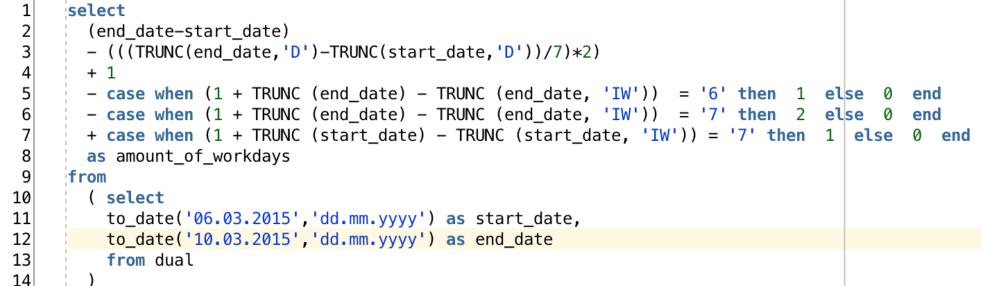
from: http://www.apex-at-work.com/2015/03/oracle-sql-calculate-amount-of-workdays.html
start_date와 end_date로 주어진 두 날짜 사이에 존재하는 일하는 날을 구하는 쿼리다. 뭐 억지로 발굴해낸 쿼리긴 하지만 SQL의 매력에 빠져드는 개발자라면 이 기능을 SQL 쿼리를 사용해 작성할 수 있다. 흠… 나쁘지 않을 것 같은데???

정~말~ 나쁘지 않다고 생각하면??? 아래 그림을 한번 살펴보고 한번 다시 생각해보는게 좋겠다.
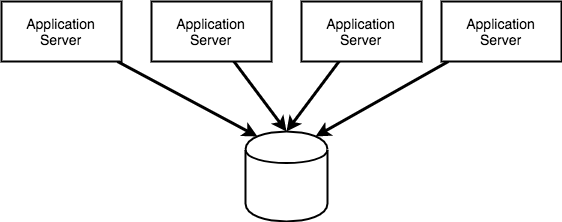
이 그림이 주는 가장 큰 시사점은 뭘까? 바로 장비 대수이다. Application Server는 4대이고, 데이터베이스는 1대이다. 위 쿼리는 극단적인 예이지만, 데이터를 읽어들이기보다는 데이터를 이용한 연산, 심지어 내부적으로 분기문에 해당하는 CASE 구문까지를 사용한다. 이런 계산을 1대 밖에 없는 데이터베이스에 부탁한다면 어떨까? 시키는 일이니까 하긴 하겠지만 데이터베이스라는 친구는 열불이 나서 속이 터져나갈 지경이 될 것이다. 이에 반해 어플리케이션 서버는? 데이터베이스가 결과를 안주니 놀면서 유유자적한 시간을 보낼 수 밖에 없다.
이런 식의 안이한 혹은 편리한 시스템 개발은 결국 병목을 만들어낼 수 밖에 없다. 물론 잘 설계된 DB 구조와 적절한 “어플리케이션 – 데이터 계층”간 역할 분담이 정의된다면 이런 일은 크게 발생하지 않는다. 하지만 데이터는 시스템의 동작하는 가장 바탕이 되고, 이를 가공처리하는 단계 단계를 통해 우리가 제공하는 서비스가 완성된다. 그 과정에서 MSG같은 RDBMS가 있다. 시간에 쫓기는 개발 세상에서 쉽지 않은 유혹이다.
그럼에도 불구하고 우리는 유혹에 맞써야 한다. 어플리케이션 서버가 HTTP/TCP Connection을 받아서 Business Logic에 해당하는 SQL 문장을 DBMS에 던지는 역할만 한다면 이름에서 “어플리케이션” 이라는 단어를 빼야한다. 그렇기 때문에 처리에 필요한 데이터를 불러들여 어플리케이션에서 실행해야할 로직을 합당하게 실행해야 한다. 이 과정에서 DBMS는 효과적인 데이터 관리를, 어플리케이션 서버는 합당한 로직의 완성을 위한 계산과 판단을 수행해야한다.
다른 관점에서 시스템은 횡적 확장(Scale out)이 가능하게 설계되고 개발되야한다. 시작은 미미했으나 그 끝이 창대할려면 말이다. 하지만 RDBMS에 의존한 시스템은 명확한 한계를 갖는다. RDBMS는 높은 성능을 발휘하기 위해서는 Scale Out 방식의 확장 모델보다는 Scale Up 방식이어야 하기 때문이다.. 왜? 당연히 데이터를 다루는 작업을 해야하니까! 어떻게든 많은 데이터를 한꺼번에 처리할려면 많은 메모리가 필요고 또한 인메모리 데이터를 빠르게 소모시킬려면 많은 CPU(Core)가 필요한건 당연한 이야기니까. 오라클의 RAC를 이야기할지 모르겠지만, 어찌됐든 오라클도 개별 장비는 좋아야 한다는 사실에는 변함이 없다.
데이터베이스, 다시 한번 생각해보자!
좀 더 높은 관점에서 우리가 데이터베이스를 어떻게 사용하는지 살펴보자. 시스템은 혼자서는 존재할 수 없으며, 많은 경우에 다른 서비스 시스템과 이야기를 주고 받아야 한다. 서비스간의 Collaboration을 통해 궁극적으로 사용자가 원하는 기능에 도달할 수 있다. 서비스간의 소통을 위해 데이터의 교환은 필수적이다. DBMS는 그런 관점에서 아주 요긴한 도구가 될 수 있다.
아래 그림에서 알 수 있는 바와 같이 서비스들이 하나의 데이터베이스를 공유한다면 RESTful과 같은 번잡한 프로토콜을 통해 데이터를 주고 받는 것을 최소화할 수 있다. 뭐하러 그 많은 데이터를 서로 주고받는가? 데이터가 존재하는 테이블의 스키마를 안다면 기초적인 정보를 가지고도 충분히 원하는 데이터를 획득할 수 있는데… 오직 필요한 건 DBMS에 연결만 하면 된다!
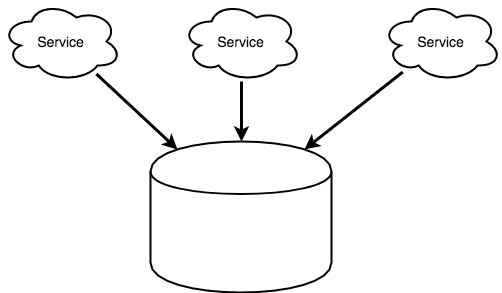
하지만 여기에서도 마찬가지로 성장의 딜레마에 빠진다. 더 많은 서비스들이 하나의 물리적인 데이터베이스로 매개화된다면 결국 이 부분이 병목 구간이 된다. 병목 구간일 뿐만 아니라 치명적인 아킬레스 건이 될 수도 있다.
- 한 서비스에 공유된 데이터베이스에 과도한 데이터 처리를 유발한다고 가정해보자. 이 부하는 그 서비스만의 문제가 아니다. 궁극적으로는 연결된 모든 서비스들에 영향을 준다. 부하를 유발한 서비스의 입장에서야 자신의 기준에 부합한다고 생각하지만 다른 서비스들은 뭔 죄가 있겠는가? 이 상황에 대한 당장의 타계책은 결국 DBMS를 확장하는 방법 이다. 다른 대안은 궁색하다.
- 보안등의 이슈로 DBMS 엔진을 업데이트 해야하는 경우가 있다고 하자. 통상적으로 엔진의 업데이트는 데이터베이스 접근을 위한 클라이언트 모듈의 업데이트를 동반한다. 뭔말이냐하면 엔진을 업데이트하고 정상적은 데이터베이스 연결을 위해서는 모든 서비스들에서 동작되는 모든 어플리케이션의 일괄 패치를 의미한다. 국내에서 이런 일괄 패치를 진행하는 시점은 추석이나 설날 같은 명절날이다. 개발자들이 종종 명절임에도 불구하고 고향에 내려가지 못하는 불상사가 발생한다.
데이터베이스에 대한 과도한 의존은 개발자 자신의 문제일 뿐만 아니라 조직 전체에 영향을 줄 수 있는 파급력을 갖는다. 그렇기 때문에 데이터베이스를 대하는 올바른 자세가 개발자들에게 더욱 더 요구된다고 볼 수 있다.
그래서 우리는…
이제 정리를 해볼려고 한다. 먼저 언급할 부분은 “개발자의 관점에서 DB를 어떻게 바라볼 것인가?” 라는 점이다.
RDBMS든 뭐든 데이터베이스는 데이터의 저장소이다. 물론 MSG 역할을 하는 좋은 데이터베이스라면 더욱 좋을 것이다. 하지만 우리가 생각해야할 점은 “데이터를 저장”하는 역할이 데이터베이스라는 사실이다. 그 이상을 바란다면 당신은 개발자가 아니라 DBA가 되야 맞다. 데이터라는 관점에서 RDBMS에 대해 다음의 사항을 고려하면 좋겠다.
- 어떤 데이터를 저장할 것인가? 경우에 따라 굳이 데이터베이스에 저장할 필요가 없는 데이터임에도 불구하고 이를 저장해두는 경우가 있다. 예를 들어 1년에 한번 특정한 이벤트에 맞춰 변경하는 1~2k 건수의 데이터들이 있다고 하자. 이 데이터를 굳이 데이터베이스에 저장할 필요가 있을까? 가장 빠른 데이터의 저장소는 어플리케이션의 메모리 영역이다. 그럼 당연히 메모리에 이 데이터를 상주시키는게 맞고, 이를 위한 코드를 작성하면 된다.
- 얼마나 간편하게 저장하고 데이터를 로딩할 수 있는가? 데이터는 데이터 자체로 접근하는게 맞다. 앞서 언급한 경우와 마찬가지로 복잡한 Biz Logic을 뒤섞은 SQL 쿼리로 데이터를 로딩한다고 보자. 개발자인 당신이 그 로직을 테스트 케이스를 통해 신뢰성이 있다는 것을 보장할 수 있을까? 당연히 없다. 가장 간단한 형태로 로딩하고 로딩된 결과를 Biz Logic으로 테스트 가능하도록 만들자. 이를 위한 방안으로 JPA와 같은 여러 프레임웍들이 이미 존재한다. 찾아보면 각 언어별로 다 나온다.
- iBatis/MyBatis를 사용하더라도 쿼리가 한 페이지를 넘는다면 이미 상당히 꾸리하다라는 증거다. 절대 쿼리는 1페이지 이내에서 결론을 내야한다. 그 이상 넘어가는 쿼리는 이해하기도 힘들뿐만 아니라 읽기도 힘겹다. SQL도 프로그래밍 언어다. 여기에서도 클린 코드를 실현해야하지 않을까?
- 마지막으로 원론적인 이야기지만 데이터를 무조건 RDBMS에 저장할려고 하지 마라. 아는게 무서운거라고 알기 때문에 RDBMS에 무조건 넣을려는 경향이 있다. 다양한 통계를 만들겠다고 웹 엑세스 로그를 RDBMS에 넣고 돌리는 행위가 과연 맞는 짓일까? Transactional Queue를 만들겠다고 그 데이터를 RDBMS에 넣고 넣었다가 뺏다하는 짓이 과연 맞는 짓일까? MongoDB, Elasticsearch, DynamoDB 혹은 심지어 Hadoop도 사용할 수 있다.
마이크로서비스 아키텍쳐에서 DBMS의 역할
개발자의 관점뿐만 아니라 이제 데이터베이스의 관점을 아키텍쳐의 관점에서도 새롭게 봐야할 시점이다. 특히나 마이크로서비스 아키텍쳐 환경에서는 더욱 더 데이터베이스의 역할을 어떻게 정의할지를 좀 더 깊게 생각해야 한다.
마이크로서비스 아키텍쳐는 세분화된 서비스가 독립적인 형태가 되는 것을 지향한다. 개별 서비스는 자신과 관련된 자원을 독립적으로 운영하고, 자원에 대한 다른 서비스에 대한 의존성을 없애야 한다. 이유는 간단하다. 그래야만 단위 서비스가 보다 빠르게 움직일 수 있기 때문이다.
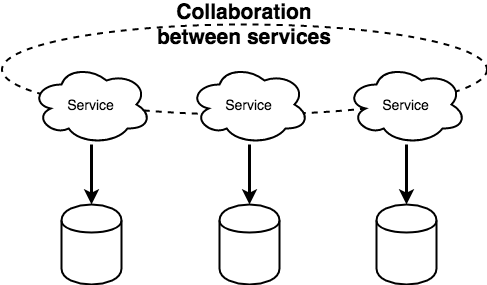
앞서 설명한 예시와 같이 서비스간 데이터베이스와 같은 자원이 공유되는 상황에서는 자원에 의한 의존성 문제로 원하는 시점에 원하는 형태로 서비스를 개발하기 어렵다. 특히나 정서상 이미 있는걸 쓰라고 강요하는 경우가 비일비재하다. 이런 간섭이 존재하는 상황에서는 자유로운 데이터 저장소로써의 데이터베이스의 사용이 어렵다.
독립적인 서비스의 개발/배포/운영이 이뤄지는 상황이라면 각 상황에 적합한 데이터 저장소를 활용할 필요가 있다. 마이크로서비스 세상은 이를 권장할 뿐만 아니라 개발자로써 환경에 적합한 물건을 사용해야만 한다. 그래야 최적의 성능을 낼 수 있을 뿐만 아니라 서비스간 유기적인 협업이 가능하니까.
개발자가 거버넌스 혹은 좋은게 좋은거니까에 익숙해지면 개발자가 정말 해야할 개발 혹은 코딩을 잊게 된다. 좋은 도구는 활용하면 최선이겠지만, 그에 앞서 자신의 발전을 위해 놓지 말아야 하는 “개념”에 대해서는 항상 생각해보는게 좋겠다.
– 끝 –
ps. 글의 처음을 쓴지는 반년이 넘은 것 같은데 완전하지 않지만 가락이 대강 갖춰진 것 같다. 말이 말은 만드는 것 같기도 하고 원래 내가 하고 싶은 말이 이 말이었나 싶기도 하다. 코딩하는 것과 마찬가지로 글도 생각이 있을 때 마무리짓는게 최선인 것 같다.